Chapitre 3- Représentation Vectorielle des mots, Word2Vec et Glove
Word2Vec
On se souvient que l’approche retenue pour Word2Vec est celle du skip-gram qui considère une fenêtre glissante de taille fixée se déplaçant successivement d’un mot à l’autre d’un texte pour analyser le mot central de cette fenêtre et son contexte, c'est-à-dire les mots associés à ce mot central, de chaque coté.
La probabilité d’un mot du contexte est exprimée sous la forme d’une probabilité conditionnelle dépendante du mot central et suivant une loi softmax.

La fonction objective à minimiser dépend donc non seulement des mots présents dans la fenêtre à l’instant t, mais aussi de tous les mots présents dans le vocabulaire (V) et donc les probabilités conditionnelles servent à normaliser celles des mots de la fenêtre. Avec un vocabulaire contenant des dizaines voire des centaines de milliers de mots, le calcul des gradients est très long et met en jeu une large proportion de vecteurs mots creux.
Stochastic Gradient
C’est pour cela que l’approche en Stochastic Gradient est utilisée, chacun des mots vecteurs étant mis à jour après chaque itération du calcul des gradients. Mais d’autres optimisations existent comme le Negative Sampling.
Negative Sampling
Le facteur de normalisation de la fonction softmax étant très lourde à calculer, on utilise une approche requérant moins de mots vecteurs mais introduisant des mots parasites pris au hasard dans le vocabulaire et agissant comme un bruit statistique renforçant la phase d’apprentissage.
L’idée de bain est d’entraîner les nœuds de régression logistique en utilisant une paire de mots vecteurs réels (mot central et mot présent dans son contexte) et une paire de mots parasites (mot central et mot pris au hasard dans le vocabulaire).

Le premier terme de la fonction objectif correspond aux paires réelles donc les probabilités sont à maximiser alors que le second terme correspond aux paires parasites dont les probabilités sont à minimiser.
Co-occurrence de mots vecteurs
Une des méthodes pour alléger les calculs est de travailler uniquement sur des paires de mots qui existent dans le corpus textuel, soit dans la fenêtre glissante soit dans le texte dans son entier.
- Si on ne cherche les co-occurrences dans une fenêtre, la méthode est similaire à Word2Vec et elle capture à la fois l’information syntaxique et sémantique.
- Si on les recherche sur le document en entier, alors on va capturer les sujets généraux du texte, ce qu’on appelle l’analyse sémantique latente.
- I like Deep Learning
- I like NLP
- I enjoy flying
La matrice de co-occurrence pour une fenêtre de taille 1 (mots adjacents) est la suivante :

Le problème avec cette matrice de co-occurrence est que sa taille augmente avec le vocabulaire utilisé et qu’elle est lourde à stocker. Elle est aussi très facilement biaisée par le caractère creux inhérent à son mode de remplissage. Les modèles basés sur de telle matrice peuvent être moins robustes.
Une idée pour réduite la taille de la matrice est de réduire sa dimension en utilisant des vecteurs plus denses en information afin de se limiter entre 25 et 1000 dimensions comme c’est le cas pour Word2Vec.

Une méthode pour réduire la dimension des vecteurs composant la matrice est d’utiliser le mapping en Singular Value Decomposition de la matrice (similaire au principe de ACP). Cela est facilement faisable en Python grâce au module Numpy.
Dans cet espace à dimensions réduites les mots s’organisent suivant les co-occurrences dans les composantes principales.

Il est utile de avant de traiter le texte de le pré-processeur afin de retirer les mots les plus fréquents (articles, pronoms personnels, etc.…) mais sans vraie information sémantique ou syntaxique.
Le problème avec le SVD est son coût : pour une matrice n x m, O(mn²).

Glove (Global Vectors model)
Dans la méthode Glove développée par Stanford, on fait un peu le meilleur des deux approches en ne travaillant que sur les paires de mots apparaissant dans la matrice de co-occurrence définie sur tout le texte (Pij) et en utilisant une fonction objectif très proche de celle vue précédemment pour la méthode Word2Vec.
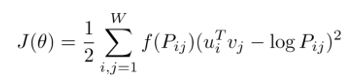
La « fonction objectif » doit donc maximiser le premier produit de mots vecteurs (vecteur colonne et vecteur ligne définis pour chaque mot) et minimiser le second terme en log qui correspond à des associations de mots provenant de la matrice de co-occurrence définie à l’échelle du texte entier.
La fonction f permet de pondérer à volonté l’influence des mots suivant leur fréquence d’apparition dans le corpus de texte.
- L’entraînement est rapide
- La méthode est flexible et s’adapte bien au gros corpus
- Les performances sont bonnes même sur les corpus petits et les mots vecteurs de faible dimension
Comme c’est le cas pour la méthode Word2Vec traditionnelle, un mot a en fait deux vecteurs : l’un définissant les mots en vecteur colonne (V) et l’autre les définissant en vecteur ligne (U).
Il s’avère que la somme U + V permet de capturer efficacement l’information sémantique et syntaxique des mots vecteurs. Mais toute autre option de concaténation peut être testée comme hyper-paramètre.
Evaluations des performances
Lorsque il s’agit d’analyse linguistique, on peut distinguer deux types d’évaluation des performances : les méthodes intrinsèques et les méthodes extrinsèques.
- Les méthodes intrinsèques sont relatives à des tâches spécifiques ou de bas niveau. Elles sont rapides du point de vue du calcul. Mais elles ne sont pas suffisantes pour évaluer les performances dans le cas d’une tâche de plus haut niveau.
- Les méthodes extrinsèques sont liées à une tâche de haut niveau, elles sont plus longues à calculer et leurs résultats sont plus difficiles à analyser car plusieurs sous-systèmes agissent ensemble.
Exemple d’évaluation intrinsèque
Une méthode très connue d’évaluation intrinsèque est la recherche d’analogie entre les mots en calculant leur similitude dans l’espace d'embedding (similarité cosinus).
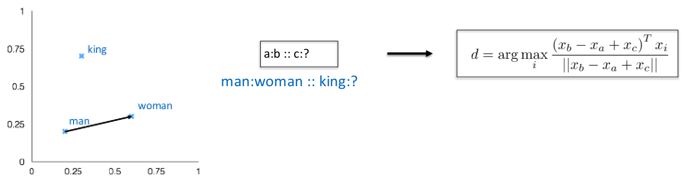
Avec ce type d’évaluation, on peut rapidement tester l’impact des hyper-paramètres comme la symétrie de la fenêtre contextuelle ou la dimension des mots vecteurs (nombre d’embeddings).
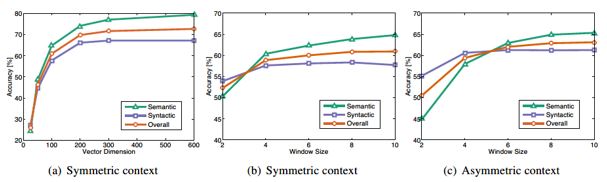
On peut voir sur les figures précédentes que la dimension optimale des mots vecteurs pour le corpus donné est autour de 300 et que la taille optimale pour la fenêtre d’analyse est autour de 8 mots. En revanche, on voit aussi qu’une fenêtre symétrique est plus efficace qu’une fenêtre asymétrique.
De même et ce n’est pas une surprise, le temps nécessaire à l’apprentissage a un impact sur les performances du modèle. Sur la figure suivante, on voit également que Glove a l’air plus rapide que les équivalents utilisant l’approche Skip-Gram.
En ce qui concerne le corpus documentaire utilisé pour l’apprentissage des similarités, Wikipedia est plus efficace que d’autres sources de textes.

Exemple d’évaluation extrinsèque
De telles méthodes d’évaluation nécessitent une référence humaine pour estimer la performance de l’analyse des similarités dans un contexte donnée, pour une tâche donnée.
Commentaires
Enregistrer un commentaire