Chapitre 2- Représentation Vectorielle des mots
Comment représenter la signification d’un mot en informatique ?
Un mot, tout comme une phrase, représente avant tout une idée, l’idée qu’une personne veut exprimer. Une des façons les plus immédiates d’exprimer une idée, c’est d’utiliser un mot, qui est finalement un symbole.WordNet
Une solution historique pour représenter la signification d’un mot en informatique est de fournir au programme des listes de synonymes ou d’hyperonymes. C’est-à-dire de coder en dur des listes de correspondances entre les mots d’un vocabulaire.
Une ressources couramment utilisée est WordNet qui comprend un nombre important de mots et leurs synonymes/hyperonymes mais manque de nuances, n’est pas mise à jour régulièrement, peut être subjectif, requiert une action humaine pour être adapté quant à son contenu et surtout, ne permet calculer de façon précise les similarités entre mots au-delà de celles entrées par l’homme lors de la création ou de la mise à jour des bases.
Représentation des mots sous forme numérique discrète
Dans l’analyse linguistique traditionnelle, on représente un mot sous la forme d’un vecteur défini par rapport à un ensemble déterminé de mots (vocabulaire). Ce vecteur est appelé one-hot vector :- Supposons un vocabulaire contenant W mots dont les mots hôtel et model en place i et j,
- hôtel = vecteur [0 0 0 0 0 …. 1 …. 0 0 0] de dimension W avec 1 en i ème position,
- motel = vecteur [0 0 0 1 0 0 ….. 0 0 0] de dimension W avec 1 en j ème position.
Cette représentation des mots par des vecteurs creux (sparse vector) n’est pas optimale tant du point de vue de la gestion mémoire que des possibilités offertes par une telle représentation. Entre autre, il n’est pas possible de déterminer la similarité de deux mots en utilisant de tels vecteurs car ils sont tous orthogonaux entre eux : leur produit scalaire est nul alors que deux mots peuvent être très proches de par leur sens comme c’est le cas pour hôtel et motel. Afin de répondre à cette problématique de détermination de similarité, il a été proposé d’encoder cette information directement dans les vecteurs eux-mêmes. C’est le principe de l’approche en « word embedding ».
Représentation d’un mot par son contexte
L’idée centrale est que la signification d’un mot est donnée par les mots qui lui sont souvent associés, définissant son contexte. Cette idée simple mais pas forcément intuitive est l’idée la plus puissante implémentée par les techniques d’analyse linguistique modernes. La construction du contexte fréquent d’un mot est basée sur l’analyse probabiliste d’une multitude de textes contenant ce mot.
Par exemple, le mot/adjective bancaire a 3 contextes différents dans ces 3 phrases :
… les problèmes de dette nationale sont transposés à la crise bancaire comme en 2009…
… l’Europe doit unifier sa régulation bancaire afin de répondre aux défis nouveaux…
… l’Inde vient de pénalise son propre système bancaire en votant la loi …
… les problèmes de dette nationale sont transposés à la crise bancaire comme en 2009…
… l’Europe doit unifier sa régulation bancaire afin de répondre aux défis nouveaux…
… l’Inde vient de pénalise son propre système bancaire en votant la loi …
Vecteurs contextuels
Chaque mot est alors défini non pas par un vecteur creux mais par un vecteur défini par rapport à un contexte défini. Puisque un mot est défini par son contexte, deux mots similaires auront des vecteurs contextuels proches.Présentation rapide de la méthode d’apprentissage Word2Vec
Word2Vec est une méthode d’apprentissage des vecteurs de similarité basés sur les contextes des mots, proposée en 2013 par Mikolov et al.
Le processus d’apprentissage de la machine va être le miroir de l’idée présentée dans le chapitre précédent : si la signification d’un mot central est donnée par son contexte, alors la machine va apprendre à optimiser les vecteurs des mots du contexte en fonction de la probabilité d’occurrence du mot central.
Méthode Skip-Gram
Dans son implémentation originale, Word2Vec définit une fenêtre de mots contexte symétriquement définie autour du mot central. A noter que l’ordre des mots du contexte autour du mot central n’est pas un facteur d’apprentissage. Bien évidemment cette fenêtre glisse d’un mot à l’autre afin de couvrir l’ensemble des phrases formant le corpus documentaire servant à l’apprentissage de la machine.

- A l’instant t, en considérant le mot central Wt, la machine va apprendre les vecteurs représentant les mots (Wt-2, Wt-1, Wt+1, Wt+2) de la fenêtre autour de Wt de façon à maximiser les probabilités conditionnelles des mots du contexte sachant que le mot central est Wt.
- A l’instant suivant t+1, la fenêtre de recherche va juste glisser d’un cran vers la droite.
Et ainsi de suite jusqu’à la fin de la ligne, et cela pour toutes les lignes des textes utilisés pour l’entrainement du modèle. L’optimisation des paramètres du modèle est donc basée sur les probabilités conditionnelles des mots du contexte de chaque mot lorsque il est considéré comme mot central.
Fonction Objectif
Pour chaque position t entre la position 1 et la position T, en considérant le mot central Wt, alors la vraisemblance des mots du contexte est proportionnelle à la probabilité conditionnelle pour toute la fenêtre autour de ce mot central, probabilité qui peut être calculée comme produit des probabilités conditionnelles individuelles de chacun des mots du contexte.
En général on préfère minimiser une « fonction objectif », souvent en appliquant un algorithme de gradient, et donc on peut modifier la fonction de vraisemblance précédente de façon à en faire une « fonction objectif » en passant par le log pour transformer les produits en sommes plus faciles à dériver:

Utilisation de la fonction Softmax pour le calcul des probabilités conditionnelles
Chacune des probabilités conditionnelles sont calculées à partir des vecteurs des mots, en appliquant la fonction « softmax » à leurs produits scalaires respectifs. Cette fonction permet de transformer un nombre quelque conque en un nombre positif compris entre 0 et 1 et donc assimilable à une probabilité.

Changeant une dernière fois la notation, appelons désormais :
- Vc le mot central
- Uo le mot du contexte
Pour un mot central donné, le dénominateur est toujours le même et lourd à calculer car il correspond au calcul d’une similarité globale entre ce mot central et tous les mots présents dans le vocabulaire (qui peut contenir des centaines de milliers voire des millions de mots).
Le rapport de ces deux similarités permet de normaliser la similarité du mot contextuel courant par rapport au mot central en cours.
Remarque : pour chaque mot du vocabulaire, il y a en fait deux vecteurs, un vecteur lorsque le mot est en position centrale, et un vecteur lorsque ce mot est contextuel par rapport à un autre mot central. Les paramètres à optimiser itérativement à partir du corpus d’entraînement sont principalement ses vecteurs doubles définis pour tous les mots du vocabulaire. Un unique vecteur 1D est construit à partir de ces paramètres et donné à l’algorithme d’apprentissage.
Remarque : pour chaque mot du vocabulaire, il y a en fait deux vecteurs, un vecteur lorsque le mot est en position centrale, et un vecteur lorsque ce mot est contextuel par rapport à un autre mot central. Les paramètres à optimiser itérativement à partir du corpus d’entraînement sont principalement ses vecteurs doubles définis pour tous les mots du vocabulaire. Un unique vecteur 1D est construit à partir de ces paramètres et donné à l’algorithme d’apprentissage.

Optimisation par descente de gradient
Pour optimiser la « fonction objectif », on
emploie la méthode classique de descente de gradient appliquée à chacun des
paramètres du vecteur θ.

Par exemple, le gradient de la « fonction
objectif » par rapport au mot central Vc est équivalent à :
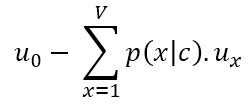
avec l'espérance de ux définie par :

Détails d’implémentation de Word2Vec
Plusieurs optimisations ont été implémentées par
Word2Vec :
- La descente de gradient ne se fait pas en mode batch mais en mode séquentiel, ce qui implique que la mise à jour des paramètres se fait après le calcul du gradient sur un sous-ensemble du corpus d’entrainement. Et que cette mise à jour est répétée de nombreuses fois sur des sous-ensembles différents mais de même taille.
- Skip-gram et échantillonnage négatif : la « fonction objectif » va maximiser la similarité entre le mot central et les mots de son contexte et minimiser en même temps la similarité entre le mot central et des mots pris au hasard dans le vocabulaire, qui sont alors appelés échantillons négatifs (negative sampling)

Autre méthodologie « Continuous Bag of Words model »
L’idée
principale est la même mais cette fois-ci, on essaye de prédire un mot central
à partir de son contexte. On est donc dans une vraie probabilité conditionnelle
et plus dans la vraisemblance bayésienne.
Commentaires
Enregistrer un commentaire